
Generowanie wyjściowego wektora regresji
Opisywany klasyfikator podąża w kierunku uśrednienia danych, które są mu przedstawione, tworzy regresję za pomocą następującego wzoru
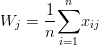 | (5.1) |
gdzie:
- W
- - wyjściowy wektor regresji,
- n
- - ilość regresji uczestnicząca w uśrednianiu,
- xij
- - j - ta komórka i - tego wektora wejściowego.
Rysunek 5.1: Przykładowe wektory wejściowe, przed procedurą uśredniania
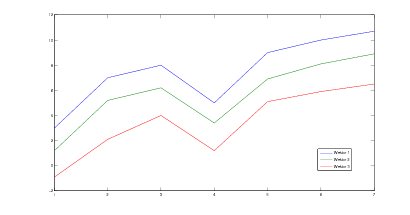
Źródło: Badania własne
Rysunek 5.2: Wynik uśredniania przykładowych wektorów
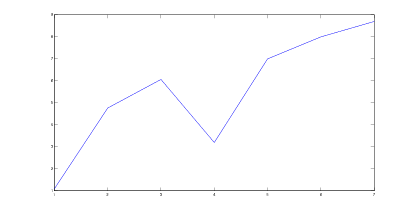
Źródło: Badania własne
Wzór 5.1 jest prostym wzorem na średnią Wj, tak więc klasyfikator BARBARA uśrednia dane otrzymane z wstępnej klasyfikacji. Aby to zobrazować, rysunek 5.1 przedstawia 3 najlepiej dopasowane wektory, które będą poddawane procesowi uśredniania. Należy zauważyć, że jeśli będziemy posiadać zbyt małą ilość wektorów wejściowych a ich korelacja będzie zbyt mała, wówczas wynik może nie spełniać naszych oczekiwań. Jednak, gdy uśrednianiu poddajemy dużą ilość wektorów, albo wektory są do siebie korelacyjnie zbliżone, wówczas wynik przedstawia reprezentanta wszystkich wektorów uczących poddawanych uśrednianiu (rysunek 5.2 ).
Istnieją jednak wypadki w których nie chcemy aby cała regresja była uśredniana, np. gdy interpretujemy dane jako dane klasyfikacyjne. Wektory te podzielone są na zmienne (statystyki), które nie koniecznie muszą mieć charakter liczbowy, a jakościowy. Zastanowiwszy się, można dojść do wniosku, że danych jakościowych nie można uśredniać arytmetycznie. Algorytm klasyfikatora rozwiązuje ten problem w ten sposób, że sprawdza numery kolumn czy nie znajdują się na tzw. "liście zmiennych jakościowych". Gdy dana kolumna znajduje się na tej liście, jest wówczas obliczana nie średnia arytmetyczna, a dominanta - wartość modalna. Tak więc algorytm wstawia zamiast średniej wartość najczęściej występującą. Istnieje możliwość aby zmienić działanie algorytmu klasyfikatora BARBARA, żeby obliczał tylko modę z najbliższych wektorów. Należy wówczas dodać do listy zmiennych jakościowych wszystkie kolumny wektora wejściowego, co może dać ciekawe rezultaty.
komentarze
Copyright © 2008-2010 EPrace oraz autorzy prac.