
Samogłoski
Dane przedstawione w podrozdziale zostały pobrane z [1]. Oryginalnie dane były zbierane dla rozpatrzenia nowo opracowanego klasyfikatora dla wielowymiarowych szeregów czasowych. Dziewięciu mężczyzn wymawiało dwie japońskie samogłoski - A oraz E, w takiej kolejności. Dla każdej wypowiedzi powstał szereg czasowy w którym zapisane zostały parametry wypowiedzi. Dane te można interpretować dwojako, jako szereg czasowy dla którego wyliczana będzie wartość predygowana, lub jako szereg czasowy w którym będziemy estymować ostatnie elementy.
Na stronie źródłowej, udostępnione zostały dwa zbiory:
- ae.train (zbiór uczący) - 4543 wektorów, window=12,
- ae.test (zbiór testujący) - 6056 wektorów, window=12.
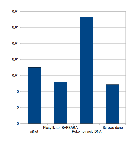
Na potrzeby badań dokonano normalizacji min-max 3.1 wektorów reprezentujących ciąg czasowy w macierzach uczącej oraz testowej, a następnie użyto tych macierzy do testowania algorytmów klasyfikacji krzywych regresji. Wyniki przedstawia tabela 12.1 oraz wykres przedstawiony na rysunku 12.1 .
Tablica 12.1: Wynik predykcji/estymacji samogłosek japońskich
| Algorytm | MSE |
| aiNet | 0,00702 |
| Klasyfikator BARBARA | 0,00516 |
| Rekombinacja DNA | 0,01332 |
| Surowe | 0,00487 |
Źródło: Badania własne
W badaniach, jako miarę błędu przyjęto MSE (wzór 10.2 ) tak więc, czym mniejszy błąd tym lepiej algorytm spełnia swoje zadanie. Dodatkowo przeprowadzony został eksperyment na surowych danych (oryginalnym zbiorze uczącym), które zostały znormalizowane metodą min-max. Jest to swego rodzaju znacznik idealności. Te algorytmy, które zbliżyły się do wyniku eksperymentu na surowych danych, są najlepsze.
Rysunek 12.1: Wykres MSE dla poszczególnych algorytmów - Samogłoski
Źródło: Badania własne
komentarze
Copyright © 2008-2010 EPrace oraz autorzy prac.